
Harness Engineering · Agentic-Native · EdTech
repo privado · IP protegida
ILC-HUB
Integrated Learning Core
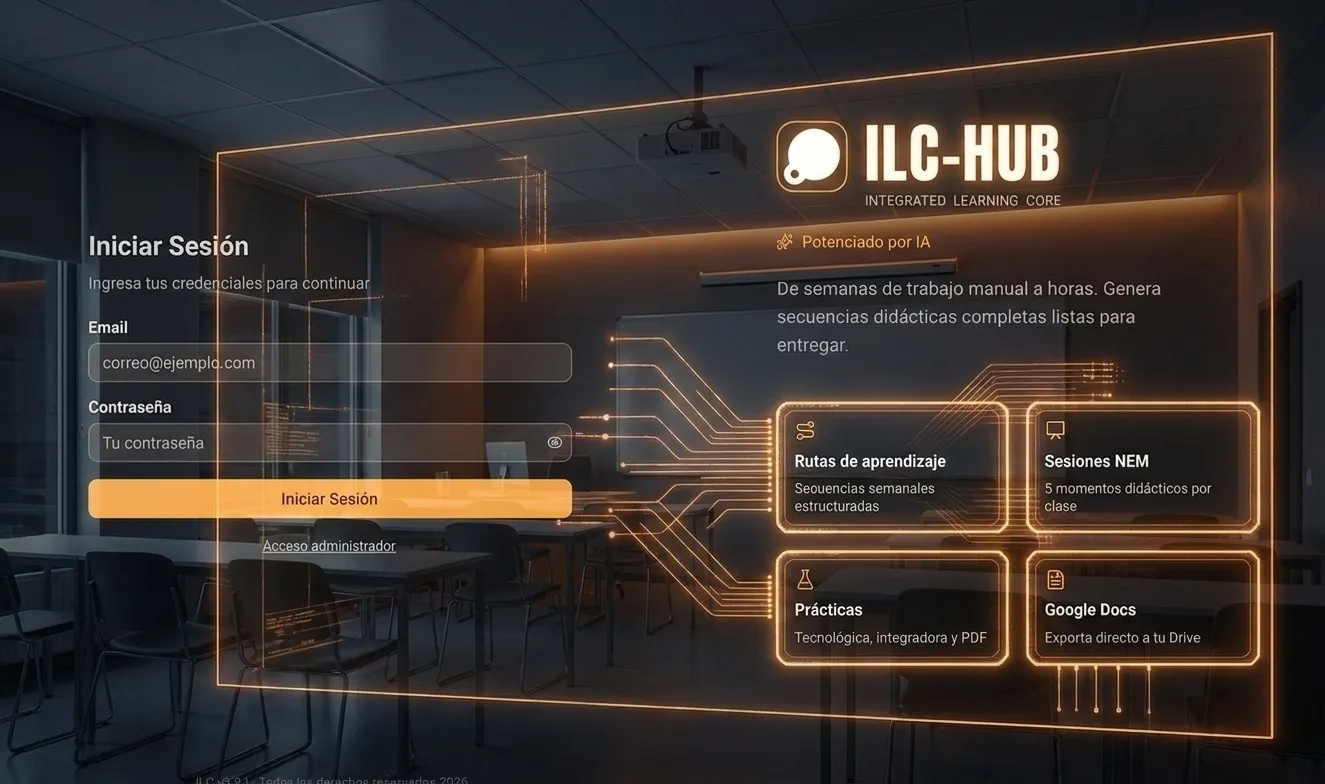
Un wrapper resuelve la API. Un harness resuelve el problema. ILC-HUB es una plataforma AI-native para EdTech construida desde un problema vivido ocho años en aula: la planificación didáctica que toma dos a tres semanas por asignatura y termina con cuatro profesores enseñando el mismo concepto de cuatro formas distintas, sin sistema compartido. El harness reduce ese trabajo a treinta o cuarenta minutos y devuelve coherencia global a doscientas cincuenta páginas de planeación. En operación con usuarios reales desde principios de 2026, con la responsabilidad por cada output anclada en una persona, no en el algoritmo.
Versiones
-
09/2024
v1
El germen: primeras pruebas de generación asistida, aún en prototipo
-
01/2026
v2
Primer núcleo del harness: de prototipo a sistema con interfaz propia
-
04/2026
v3
En producción y a escala: multi-asignatura, cada output trazable y −30% de costos
-
en curso
v4
Siguiente salto: evolución hacia una arquitectura agéntica
30–40 min
por asignatura (antes 2–3 semanas)
−30%
en costos de IA
250 pp.
de planeación coherente
2+ años
en producción real
