
Harness Engineering · Agentic-Native · EdTech
private repo · IP protected
ILC-HUB
Integrated Learning Core
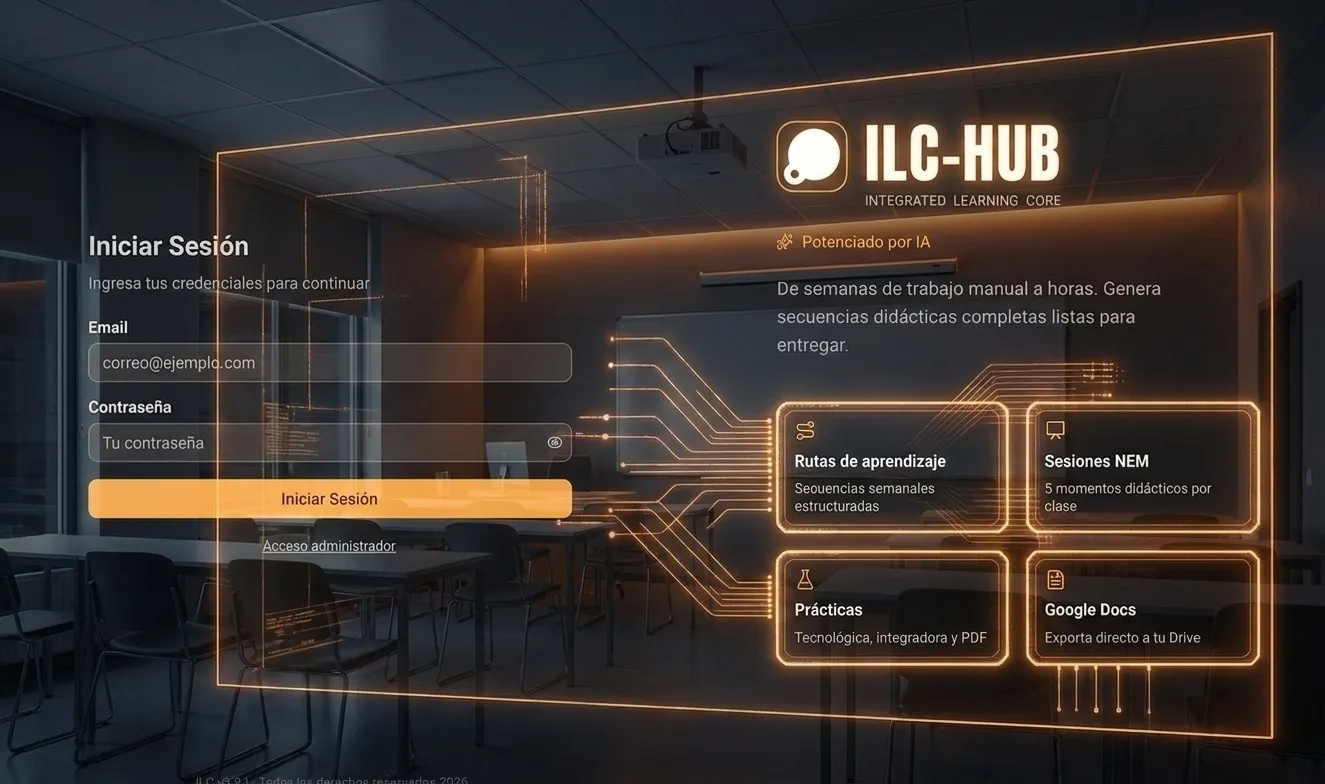
A wrapper solves the API. A harness solves the problem. ILC-HUB is an AI-native EdTech platform built from a problem lived through eight years in the classroom: lesson planning that takes two to three weeks per subject and ends with four teachers teaching the same concept four different ways, with no shared system. The harness cuts that work to thirty or forty minutes and restores global coherence to two hundred fifty pages of planning. In operation with real users since early 2026, with responsibility for every output anchored in a person, not the algorithm.
Versions
-
09/2024
v1
The seed: first assisted-generation tests, still a prototype
-
01/2026
v2
First harness core: from prototype to a system with its own interface
-
04/2026
v3
In production and at scale: multi-subject, every output traceable, −30% costs
-
in progress
v4
Next leap: evolving toward an agentic architecture
30–40 min
per subject (was 2–3 weeks)
−30%
in AI costs
250 pp.
of coherent planning
2+ yrs
in real production
